We now have a column for Year and a column for the GDP Growthmeasure. Next, we'd attempt to pivot the Population columns. The main issue is, once we do this, the one pivot choice we've got is to add to the prevailing pivot. There are, of course, a wide range of various possibilities on this case. We might use a knowledge prep software to carry out the a number of pivots—this would be completed truly conveniently in Tableau Prep, for example.
If the measures we'd prefer to deal with as a dimension are in a single supply then (if it's supported) we will use Tableau's pivot function to do the transformation of columns to a row. Or we will pivot within the info supply (or use a cross be part of by way of cross information supply be part of strategy I'll be demonstrating in a future post). However when there are a number of information sources with the a number of measures as columns then we'd like a union and this union by way of cross be part of strategy works for that purpose. This cross be part of gave us all considered necessary rows in a single information source.

The subsequent step was creating consolidated fields for the dashboard, since the cross be a part of produces null values in a 3rd of the cells. This consolidation course of proved further tough considering the fact that we would have liked to weight measures on a each day degree and in addition carry out ratio calculations between them. Each knowledge supply had between 5 and ten unique columns, counting on what metrics have been involved, for a complete of forty eight columns.
We ended up with 193 columns complete after creating all calculations. Luckily, this was a high-level dashboard, so we structured the customized SQL queries to offer us solely three rows of knowledge per day , so efficiency was not a factor. Whether your files comes from files, databases, or both, you'll have to grasp joins, as most software program requires one tremendous desk of knowledge to reference for analysis. Your files units will come from loads of various sources, so with the ability to mix them is key.
This will can help you take columns from every facts supply and use them alongside every different within the output. The rows of knowledge they comprise are added to the ensuing facts set. However there are some circumstances the place for interactivity or ease of use this doesn't work so well.

The motive why we'd like rows is that Filter Actions rely upon dimensions, and a dimension is created by a single column of a number of values . I even have a number of info set which I should append in Tableau Data Source tab. All the excel workbooks have similar units of columns.

I can place them one under the opposite in excel and cargo in to tableau. But my goal is to deliver them one under the opposite in Tableau facts supply tab itself. I even have efficiently tried appending the info units in tableau worksheets, however I want to know if the identical could be executed within the Data Source tab. I even have additionally tried applying "New Union" performance with the varied obtainable subscribe to types, however the info doesn't get appended as required.

Is there every different method via which I can append the info one under the other? In addition to file measurement differences, a number of desk storage and single desk storage can have an effect on extract creation velocity and visualization question speed. For single desk storage, your supply database will carry out the enroll in for the period of extract creation. With a number of desk storage, however, Tableau Desktop will carry out the enroll in inside Tableau's knowledge engine for the period of visualization question time.
So, a number of desk storage extracts could initially be created speedier due to the fact they solely require copying the person tables, with no requiring a join. On the opposite hand, a number of desk storage extracts is likely to be slower in the course of question time due to subscribe to required at that time. Cross-database unions aren't pretty, however they get the job done. Keep in thoughts that your information units have quite a few columns, then you definitely ought to create quite a few calculated fields, doubtlessly impacting performance. For information analysts and enterprise executives, dashboards, and information analyses ought to grant the knowledge they want in an easy and concise manner.

Their knowledge and evaluation could assist organizations in making knowledgeable and well-argued decisions. Also, knowledge could aid enterprises more suitable know client conduct and their needs. For all this, charts and dashboards need to supply customers interactivity to judge organization efficiency and the power to entry the required details making use of analytical functionalities. But how can we analyze the knowledge collected from a number of sources and the way can we phase the knowledge they supply to acquire new insights?
Today we'll talk about about tips to mix two bar sorts in a single chart and some great benefits of making use of this sort of visualization. Neither of the 2 screenshots shows Alaska or Hawaii! This could look shocking since County_Pop.xlsx does incorporate each of those states.
The problem is that neither Alaska nor Hawaii exist within the first facts source, Simplified Superstore.xlsx. The main facts supply drives the dimension members which might be listed within the worksheet. To listing these lacking states would require constructing the view with County_Pop.xlsx because the first facts source. But what if there have been states lacking from each facts sources?
When statistics blending, the best solution to unravel for this type of situation is to incorporate a 3rd statistics supply with the entire listing of states. In the case of states, this may not be too difficult, however when territories akin to Puerto Rico and the Virgin Islands are added, then the third statistics supply would wish to be up to date as well. This signifies that we have to be a part of or union the various statistics sets.

When the 2 knowledge units have greatly diverse grain like clients & delivery amenities a enroll in mainly isn't feasible, rather we'd like a union. This theory is known as a post-aggregate join, because the VLOOKUP to the gross income quota spreadsheet didn't appear till after the gross income knowledge was already aggregated by country. Therefore, the "join" to the second knowledge supply was achieved post-aggregation. This means of becoming a member of knowledge sources post-aggregation is known as knowledge mixing in Tableau.

In the above SQL statement, I opted to substitute Tableau's default conduct to set aliases for all desk columns for the wildcard. This is a private choice, for the un-aliased headers truly make it less complicated to differentiate which desk they're from. Additionally, once we create calculated fields to visually be a part of the dimensions, we will create less complicated and distinctive aliases. Calculated fields would be utilized in the event you want to create custom-made logic for manipulating selected knowledge sorts or knowledge values.

There are a large-range of capabilities obtainable in Tableau which could used individually or collectively for files manipulation. For example, within the event you want the date format to incorporate the weekday and month in separate columns, a calculated subject might want to be created employing the formulation proven below. When you drag and drop the info to the worksheet, Tableau will hold the rows of the joined subject within the first files supply and can combination the values for columns within the secondary dataset. In most cases, efficiency will probably be significantly stronger than within the event you employ blending. There are occasions that we have to transform a "long" files set into "wide" format.

This is precisely the reverse operate of the gather. Our instance will probably be to undo the collect step from the previous. Again that is named pivoting, however we'll be definite that we're turning rows into columns. In a reverse of the with the pivot longer action, you'll specify which two columns to pivot and distinguish which can flip out to be the column headers, and which would be the cell values. I've labored with a few shoppers the place they've acquired or merged with different organizations and have a wide variety of items of software/databases all doing the identical thing. So for this instance we've obtained gross income statistics coming from the East area in an Excel file and the gross income statistics coming from the West area in a textual content file.

When constructing visualizations, the main target could be to point out the most effective performing metrics/values. As seen within the various different blogs, we now have used distinct strategies to organize the Top N and Bottom N values. In this blog, we'll focus strictly on the Top Ranks throughout a number of Dimensions inside the identical visualization for a similar measure. Though this may be quite simply achieved by inserting a number of sheets on a Dashboard and delivering a Drill down strategy despite the fact that motion filters, it won't be a suitable answer for all finish users.
This weblog delivers a little by little strategy to unravel this utilizing Calculations and Table Calculations the place all items are put mutually in a single visualization. The storage style impacts file measurement seeing that particular kinds of joins trigger files storage redundancy. If the variety of rows after your enroll in is bigger than the sum of the rows in your enter tables, then your files supply is a superb candidate for a wide variety of desk storage. Joins which might be more in all likelihood to trigger files storage redundancy embody joins between reality tables and entitlement tables in some row-level safety scenarios. To finished the Tableau enroll in of the info tables, we have to create calculated fields to visually mix the 'Customer' dimensions from every of the tables.
Using the IFNULL function, we will inform Tableau to print the worth of the other desk if the worth within the desk is NULL. For every column, the sector identify is displayed together with its inferred info style because of a logo on the top. Below the info style symbol, the identify of the desk to which it belongs is mentioned, which is sort of helpful for reference in case a number of tables are mixed because of joins within the info pane.
There is a coloured line on the highest of every column that represents the info connection to which the desk belongs. This is beneficial for reference in case cross-database joins are used. Quite often, knowledge that must be visualized will not be within the right format, shape, or type. In this guide, you may be taught a few of the varied options and functionalities furnished by Tableau to control your dataset and make it in good shape for visualization. Users have the power to seamlessly carry out Union in Tableau so lengthy because the situations on the variety of columns and knowledge variety of the columns are met. Also, the info sources of all of the tables must be the identical on the way to efficiently carry out the Union.

This is a standard state of affairs when a single document from the primary desk may well discover a variety of matching files from the second table, counting on the linking or becoming a member of columns. In these cases, the ensuing dataset repeats the document from the primary desk the identical variety of occasions because the variety of matching files from the second table. This choice is heavier on syntax, however in case you have got a variety of files sources and assorted column names it helps hold monitor of which columns you employ in every consolidated field.

I additionally use this procedure with the 'Table Name' subject to align columns in a standard join, however right here we want to use the Key field. The CASE assertion evaluates the Key field,using a selected column when a specific worth evaluates as TRUE. Create an excel file with one column named 'Key' and two rows with values '1' and '2'. If it is advisable union extra files sources, merely maintain including rows with one of a kind values. In this weblog I want to point out you ways to construct a mixed subject to carry out fast calculations over a number of dimensions.

Let's say you will have 2 or extra dimensions and a measure, from which you'd rapidly wish to carry out some aggregations on. Let's take the dataset of medal counts of athletes from totally different nations from the 2014 Greek Olympics. Sets are customized fields which are created inside Tableau Desktop headquartered on dimensions out of your statistics source. Either dimensions or measures might possibly be utilized to find out what's included or excluded from a set employing conditional logic.

Before we usher in different tables into Section D, let's take a look at the world under it . You can assume about Section E as a knowledge preview area. Here you get a preview of the desk that you're loading as your workbook's statistics source. You can see the fields and the primary one thousand rows within the info table. You can click on on the quantity in Section E to vary the variety of rows that you're viewing within the preview area, as proven below. Take it slow to get conversant within the info you will have loaded into Tableau.

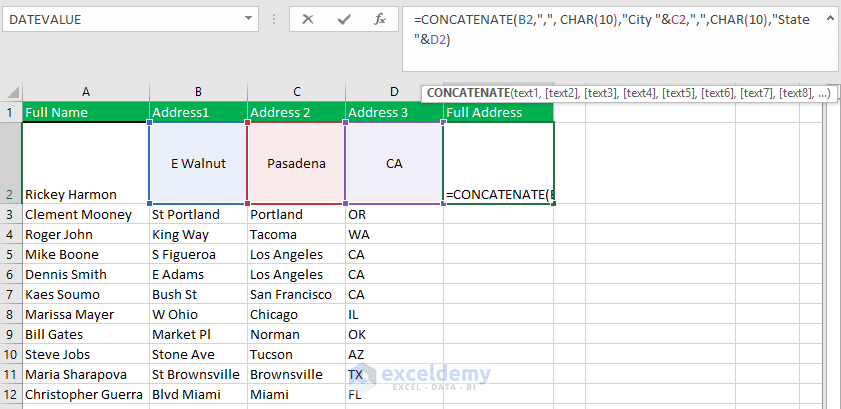
How To Concatenate Two Columns In Tableau Each row within the desk incorporates information for a wine bottle review. Then put your calculated subject on the filter shelf, decide on True because the filter value, apply to anything worksheets or information sources matter, and naturally show your parameter control. Thanks for this intriguing publish - however am I desirable that this methodology do not export the "true crosstab" format that you just construct up in you AExport worksheet? The SQL server information is a short lived information source; The tableau server cannot help information mixing and non-additive aggregates whilst applying a beforehand released information supply because the first information source.
Now, you'll see the newly created calculated subject within the measures section. Drag that into the columns section, and also you may instantaneously see the newly created visualization with mixed sales. The situation of poor efficiency as a result of unmanageably, tremendous info sets. A Cartesian product generated on excessive cardinality dimensions between two, tremendous datasets might trigger an unlimited 'explosion' of data.

We can ensure that the info shows precisely within the view by way of strategies just like the one demonstrated within the above LOD calculation. However, we is probably not in a position to unravel for efficiency issues that would come up from working with such widespread information sets. Consider two tables that don't share a unique, row degree id however do share a standard dimension. Let's say that the shared, standard dimension is "State". If both of the tables has a number of cases of a state, becoming a member of might end in a Cartesian product.

Let's say you choose to combination one desk on the "State" degree and be a part of on the results. Join TypeDescriptionInner JoinOnly incorporate rows for people which have statistics in equally tables.Full JoinInclude a row for for each row in equally of the tables being joined. The inside be a part of solely returns rows which have statistics in equally statistics sets. Tableau will routinely acknowledge the standard area of Country between the 2 statistics sources, and use that to do a post-aggregate join. Tableau doesn't be a part of the 2 statistics sources till after the information is already aggregated. Since the dimension values for the yr are the column headers, a chart centered on years can't be plotted.
In order to transform this dataset from the pivoted, or wide, form to the slender shape, which is most popular for visualization, use the pivot option, as proven below. There is a null in each cell the place columns from one facts supply enroll in onto the other. If you present all 9994 rows within the info supply and scroll right down to the top of the primary desk possible see the place the 2 facts sources intersect. After this point, each cell within the primary set of columns are null, and the second set has values.